
The most common method for uniquely identifying rows in a database is by using UUID fields. However, this approach has performance drawbacks that you should be aware of.
In this article, we will explore two performance issues that may occur when using UUIDs as keys in your database tables.
So, without further ado, let's dive right in!
What are UUIDs?
UUID stands for Universally Unique Identifier.
There are several versions of UUID, but in this article, we will focus on the most popular one: UUIDv4.
Here is an example of what a UUIDv4 looks like:

NOTE: Each UUID has the digit 4 in the same position to denote the version.
Problem 1 — Insert Performance
When a new record is added to a table, the index linked to the primary key must be updated to ensure optimal query performance.
Indexes are built using the B+ Tree data structure.
To learn more about how indexes and B+ Trees function, I highly recommend watching this excellent video by Abdul Bari.
TL;DR: for every record insertion, the underlying B+ Tree must be rebalanced to optimize query performance.
The rebalancing process becomes highly inefficient for UUIDs due to their inherent randomness, which makes it harder to maintain a balanced tree. As your system scales and you accumulate millions of nodes to rebalance, the insert performance significantly decreases when using UUID keys.
NOTE: Other options such as UUIDv7 could be a better option, since they have inherent ordering which makes it easier to index them.
Problem 2 — Higher Storage
Let's examine the size of a UUID compared to an auto-incrementing integer key:
Auto-incrementing integers consume 32 bits per value, whereas UUIDs consume 128 bits per value, which is 4 times more per row. Furthermore, when stored in human-readable form, a UUID can use up to 688 bits per value.
This is approximately 20x more per row.
Let's evaluate the impact of UUIDs on storage by simulating a realistic database scenario.
We'll use the tables from Josh Tried Coding's example:
- Table 1 will contain 1 million rows with UUIDs.
- Table 2 will contain 1 million rows with auto-incrementing integers.
Here are the results; let's break down each statistic one by one:
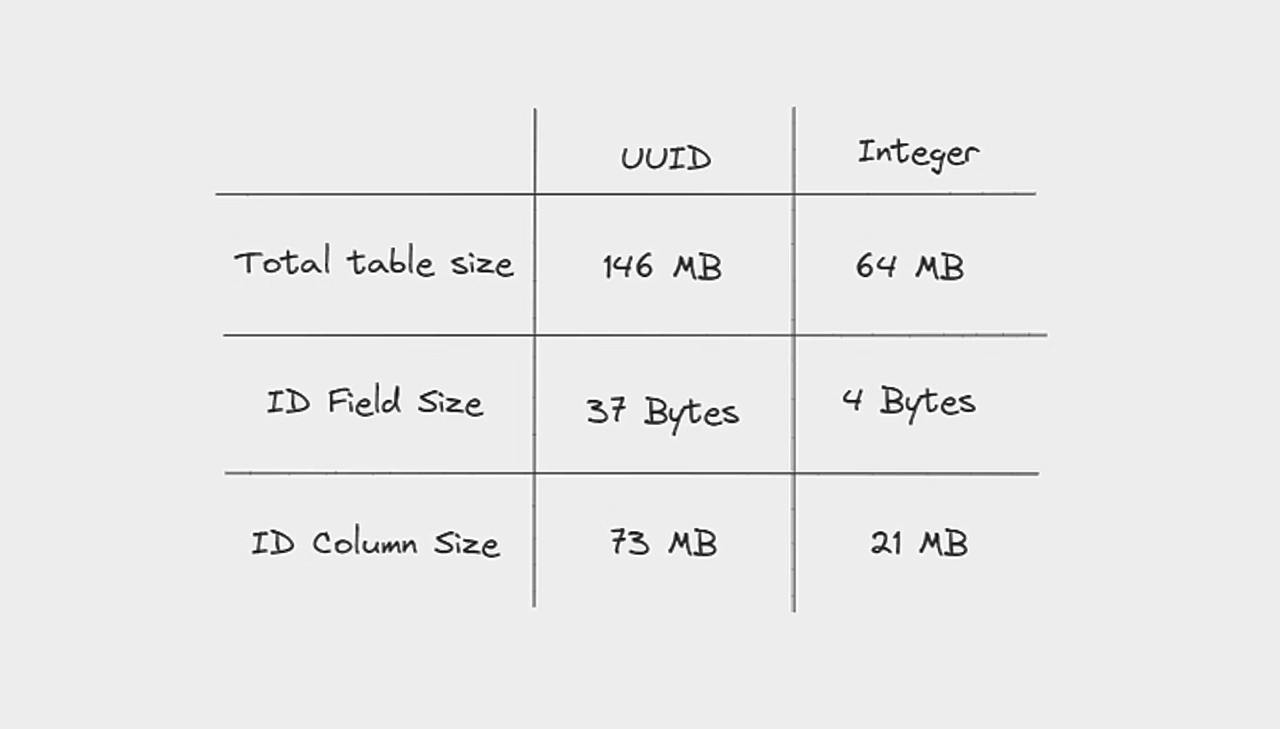
Total table size: The UUID table is about 2.3 times larger than the Integer table when considering the overall table sizes.
ID field size: A single UUID field requires 9.3 times more storage space than an equivalent integer field.
ID column size: Excluding other attributes in each table, the UUID column is 3.5 times larger than the Integer column.
Conclusion
UUIDs are an excellent method for ensuring uniqueness between records in a table.
While these issues become significant at scale, most users will not experience noticeable performance degradation from using UUIDs.
However, it is important to understand the implications of using UUIDs in your tables and ensure optimal database design to mitigate potential problems.



